计量员证书 內校员资格证 计量管理员培训 计量校准员考证 计量检定员考试 计量检测员报名 量规仪器校正员培训 内部校验员合格证 内部校准员上岗证 计量内审员岗位证 仪校员证书 计量工资质 计量师资格证书 计量证怎么考 內校证书哪里考 农产品食品检验员资格证 食品化验员证书 食品检验工培训 食品检测员考证 食品安全总监 农产品质量安全检测员 乳品检验员 油品检验员 化学检验员培训 水质检测员考试 化妆品检验员报名 微生物检验员证书 化验员上岗证 微检员证书 无菌检验员 卫生消毒产品检验员 医疗器械检验员 食品安全管理员 公共营养师 设备管理员 化学分析工考证 试验员 质检员 实验员 无损检测员 内审员 内部审核员 材料物理性能检验员 金相检验员 力学性能检验员 材料成分分析工 环境监测员资格证考试报名 圣问技术职业技能培训中心 广州圣问技术服务有限公司
化学检验员证报考的条件已确定化验员培训报名-标准差计算中分母的选择及其原因
在统计学中,标准差作为描述数据离散程度的核心统计量,其计算过程的关键在于根据数据类型(总体或样本)及样本量大小选择合适的分母(n或n-1)。这一选择直接影响估计结果的准确性,是统计学实践中必须掌握的核心技能。
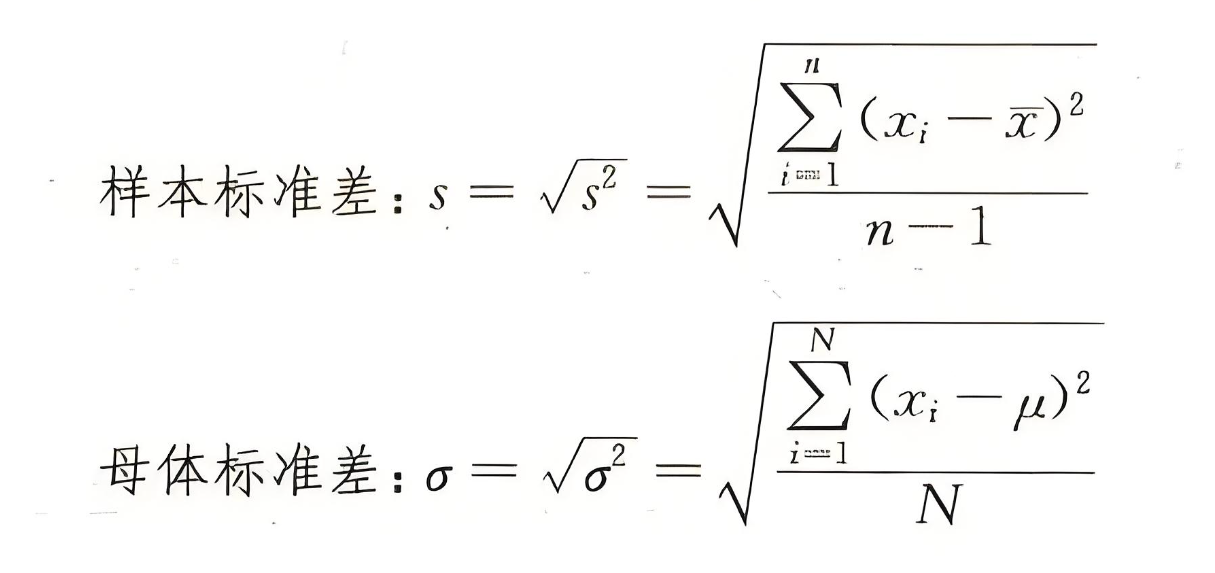
一、标准差的基础计算逻辑
无论选择何种分母,标准差的计算均以"数据与均值的偏离程度"为核心,核心步骤一致,仅在最终"平均偏离程度"的计算环节存在分母差异。具体流程如下:
1. 计算数据均值:先求出所有数据的算术平均值,作为衡量数据集中趋势的基准。例如,在分析某班级学生成绩时,需先计算全体学生的平均分。
2. 计算偏差平方和:对每个数据点,计算其与均值的差值(即"偏差"),再将所有偏差平方后求和。这一步的目的是消除偏差的正负抵消,同时放大极端值的影响,符合离散程度的统计意义。例如,若某学生成绩与平均分相差10分,其偏差平方为100分²,比原始偏差更能体现离散程度。
3. 计算"平均偏差平方":将偏差平方和除以特定分母(n或n-1),得到方差。方差是标准差计算的关键中间步骤,反映了数据与均值的平均偏离程度。
4. 计算标准差:对结果开平方,得到标准差,其单位与原始数据一致。例如,若方差的单位是"分²",则标准差的单位为"分",更符合直观理解。
二、分母选择的核心依据:总体数据与样本数据的本质差异
标准差计算中"n"与"n-1"的选择,本质是区分"总体数据"和"样本数据"的统计目的——前者追求"精确描述",后者追求"无偏估计"。
(一)分母为"n":总体标准差(或样本中心距)
当拥有全部数据(总体)时,例如某班级50名学生的全部考试成绩、某公司100名员工的全部薪资数据,此时计算的是"总体标准差",分母使用数据总个数"n"。
逻辑:总体数据的均值是"真实均值"(无误差),偏差平方和除以"n"得到的是"真实的平均偏离程度",无需修正,结果是对总体离散程度的精确描述。例如,若某班级全体学生的成绩偏差平方和为5000分²,则总体方差为5000/50=100分²,标准差为10分。
适用场景:
· 数据覆盖研究对象的全部个体,无"用部分推断整体"的需求;
· 仅需对现有数据的离散程度做简单描述(如样本中心距),不涉及统计推断。
(二)分母为"n-1":样本标准差(无偏估计)
当仅拥有部分数据(样本)时,例如从全国1000万中学生中随机抽取500人作为样本、从某品牌10万件产品中抽检200件,此时计算的是"样本标准差",分母需使用"n-1"(统计学中称为"自由度修正")。
逻辑:
· 样本均值的偏差导致标准差低估:样本均值是基于"部分数据"计算的,并非总体的真实均值,其数值会更接近样本中的数据(即"向样本中心靠拢"),导致样本内数据与样本均值的偏差平方和"偏小"。若仍用"n"作为分母,计算出的标准差会低于总体的真实标准差,出现"有偏估计"(低估离散程度)。
· 自由度修正的原理:使用"n-1"(自由度=样本量-1,自由度代表数据中"独立可变"的信息数量)进行修正,可放大偏差平方和的平均结果,抵消样本均值带来的低估偏差,使样本标准差成为总体标准差的"无偏估计"(长期多次抽样后,样本标准差的平均值会接近总体真实标准差)。例如,若样本偏差平方和为4800分²,用"n-1"=499计算的方差为4800/499≈9.62分²,标准差为3.10分,更接近总体真实值。
适用场景:
· 需通过样本数据推断总体特征(如用样本标准差估计总体标准差、进行假设检验、计算置信区间等),是统计学中分析样本数据的"标准方法"。
三、样本量对分母选择的实际影响
n与n-1的差异程度,会随样本量大小发生显著变化,直接影响计算结果的实用性。
(一)小样本(通常n≤30):n-1修正至关重要
当样本量较小时,n与n-1的比例差异较大。例如:
· n=5时,n-1=4,差异为25%;
· n=10时,n-1=9,差异约11%。
此时用"n"计算会导致标准差低估问题非常明显,甚至影响后续统计推断的可靠性。例如,若样本偏差平方和为100分²,用"n"=10计算的方差为10分²,标准差为3.16分;而用"n-1"=9计算的方差为11.11分²,标准差为3.33分,差异达5.4%。
(二)大样本(通常n>30):n与n-1差异可忽略
当样本量足够大时,n与n-1的数值非常接近。例如:
· n=1000时,n-1=999,差异仅0.1%;
· n=10000时,差异仅0.01%。
此时用"n"或"n-1"计算的标准差几乎相等,低估偏差微乎其微,对统计推断的影响可忽略不计。例如,若样本偏差平方和为10000分²,用"n"=1000计算的方差为10分²,标准差为3.16分;用"n-1"=999计算的方差为10.01分²,标准差为3.16分,差异仅0.003分。
(三)从严谨性角度,即使大样本用于推断总体,仍建议优先使用"n-1"
尽管大样本时n与n-1的差异可忽略,但从统计严谨性出发,若需通过样本推断总体特征(如估计总体离散程度、进行假设检验),仍建议使用"n-1"以保持无偏性。这是统计学界普遍接受的"保守原则",可避免因分母选择不当导致的系统性偏差。
四、实践中的操作建议
(一)明确数据类型
· 若为总体数据,分母用"n",计算总体标准差,描述真实离散程度。例如,分析某班级全体学生的成绩离散程度时,使用总体标准差公式。
· 若为样本数据(用于推断总体),分母必须用"n-1",计算样本标准差,确保无偏估计。例如,从某城市随机抽取1000名居民调查收入,需用样本标准差估计全市居民收入的离散程度。
(二)关注样本量大小
· 小样本(n≤30)时,n与n-1的差异对结果影响显著,必须坚持"n-1"修正。例如,在医学试验中仅招募20名患者,用"n"计算的标准差会显著低估总体离散程度。
· 大样本(n>30)时,两者差异可忽略,但若涉及统计推断,仍建议使用"n-1"以保持严谨。例如,分析10000名用户的消费数据时,尽管用"n"或"n-1"差异极小,但为确保无偏性,仍推荐"n-1"。
(三)区分统计目的
· 仅需描述现有数据的离散程度(无推断需求),可用"n"。例如,计算某批次产品尺寸的波动范围,仅用于内部质量控制,无需推断总体。
· 若需通过样本推断总体特征(如估计总体离散程度、进行假设检验),无论样本量大小,均需用"n-1"。例如,用样本标准差计算总体均值的置信区间时,必须使用无偏估计。
五、总结
标准差计算中分母的选择,是统计学从"描述"走向"推断"的关键桥梁。理解"n"与"n-1"背后的逻辑——总体数据的精确描述与样本数据的无偏估计——是掌握统计推断的核心。在实践中,需结合数据类型、样本量大小及统计目的,灵活选择分母,确保分析结果的准确性与可靠性。这一选择不仅影响单个统计量的计算,更关乎后续假设检验、置信区间等高级统计推断的有效性,是统计学实践中不可忽视的细节。










